![]() 位置:
位置:
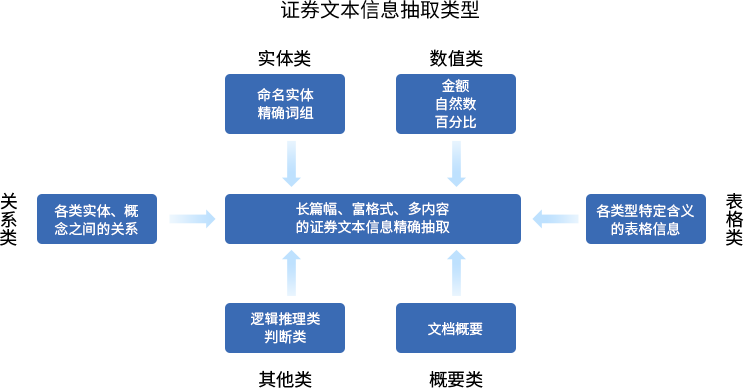
证券文本信息抽取技术研究以证券市场文本信息为对象(侧重在上市公司公开披露的定期公告、临时公告等公告信息),研究利用自然语言处理技术,从披露公告中抽取指定的文本信息。 课题针对抽取技术框架、信息抽取流程以及多种不同类型字段开展研究,并基于研究结果构建了覆盖实体类、数值类、关系类、表格类、概要类、其他类等多种类别的信息抽取平台。
课题成果
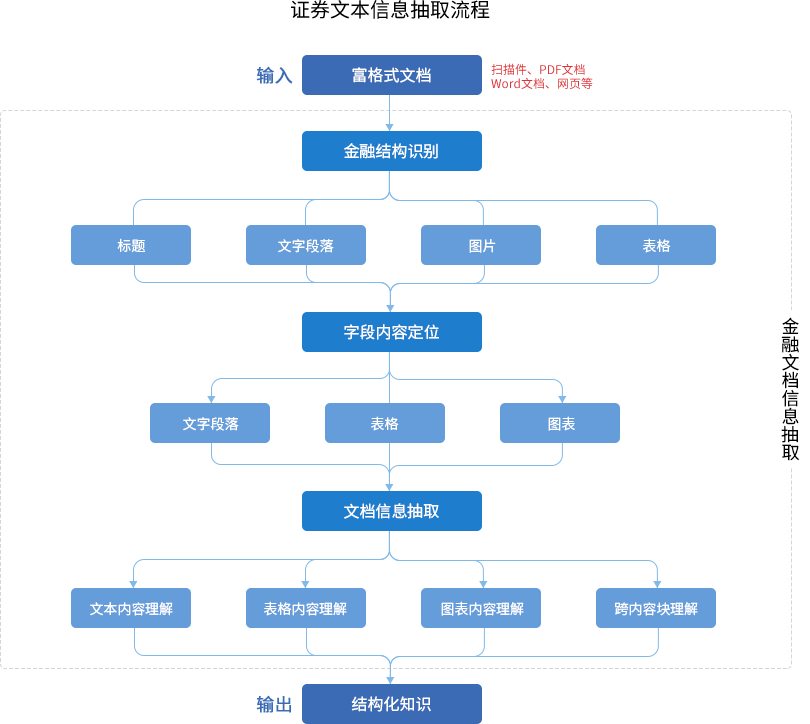
课题以上市公司重大资产重组为场景,完成了六大类文本信息抽取技术的研究。针对金融领域文档的文档格式及文本行文特点,探索出以金融文档结构识别、字段内容定位、信息抽取为关键环节的抽取流程,并实现了信息抽取的原型系统。
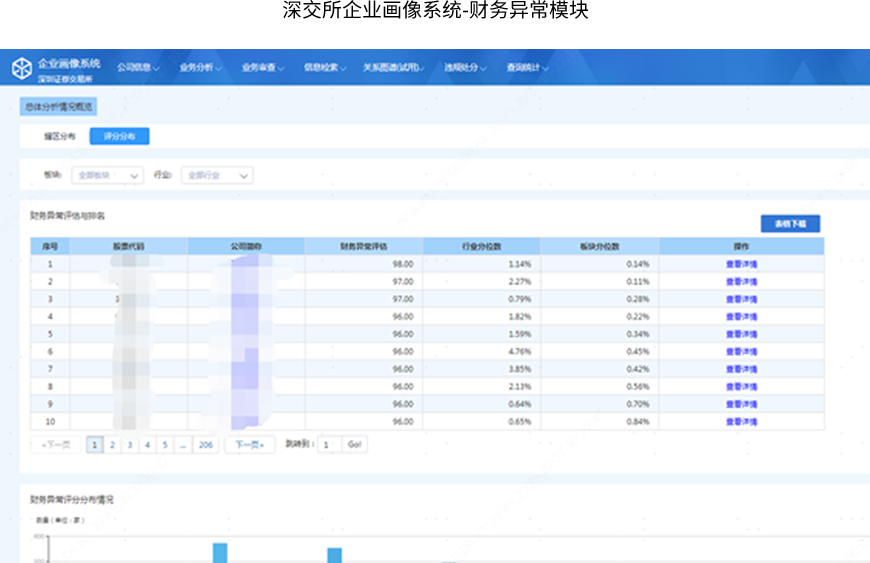
目前上市公司数量逐年增多,监管要求不断提高,上市公司舞弊手段越发隐蔽。该课题借助大数据、人工智能等新技术,并融合传统财务分析逻辑框架及经典专家经验,对上市公司财务报表进行建模分析。模型能够预测识别发生舞弊或财务异常的公司,并对其财务异常给出业务解释,并提示发生财务异常的动机。
阶段成果
• 基于财务异常模型对2019年深市上市公司进行财务异常预测,准确率80%+;
• 配套建设了财务异常分析可视化建模平台,能快速进行建模,预测识别公司是否发生财务异常。未来可推广至发债公司、IPO企业的财务异常建模分析。
模型框架及系统效果图